Merhaba,
vSAN ve Arıza Senaryoları isimli bu yazımda sizlere vSAN altyapılarında oluşabilecek disk arızalardan ve bu arızaların sonucunda ne gibi sorunlar ile karşılaşacağınızdan bahsedeceğim.
Daha önce vSAN ile ilgili yazmış olduğum makalelere aşağıdaki linkten ulaşabilirsiniz.
https://www.tayfundeger.com/kat/VSAN
Daha önce vSAN ile ilgili bir çok makale yazdım ancak disk arızaları ve hata senaryoları ile ilgili detaylı bir makale yazmadığımı farkettim. Bu yazımda vSAN ortamında cache ve data disklerinin bozulması durumunda oluşabilecek sorunlarada anlatacağım.

vSAN ve Arıza Senaryoları
Bu makaleyi okumadan önce aşağıda belirteceğim makaleleri okumanızı tavsiye ederim.
Bir ESXi host vSAN içinde bir disk arızalanırsa ve hata kodları vSAN tarafından tespit edilirse, etkilenen tüm bileşenler bozulmuş olarak işaretlenir ve vSAN, bunu yapmak için mevcut kaynaklar varsa verilerin yeni bir kopyasını oluşturmaya çalışır. Kullanılabilir kaynak yoksa, arıza çözülene kadar bekleyecektir. Bu süre boyunca, bu hatadan etkilenen sanal makineler hala kullanılabilir olacak ve çalışmaya devam edecektir. Cache disk’i arızalanırsa, vSAN tüm disk grubunu bozulmuş olarak işaretler.
Bir disk uyarı vermeden arızalanırsa (hata kodu algılanmazsa) vSAN, altyapıda bulunan tüm etkilenen bileşenleri yok olarak işaretler ve 60 dakikalık bir delay timer başlatılır. Delay timer diye bahsettiğim aslında Resyncing Objects işlemi. Bir diskin bir ESXi host üzerinden yanlışlıkla çıkarıldığı ve diskin bu zaman penceresi içinde geri yerleştirilmesi durumunda, bileşenlerin yeniden senkronize edildiği ve bir vSAN’ın normal şekilde devam ettiği bir senaryo olabilir. 60 dakikalık delay timer süresi dolarsa, yok olarak işaretlenen bileşenler, cluster’da bulunan diğer host’larda yeniden oluşturulur. Tabi burada yeterli kaynak olduğunu varsayıyorum.
Bu konu ile ilgili aşağıdaki makalemi inceleyebilirsiniz.
Genel bir giriş yaptıktan sonra minimum konfigurasyon ile hata senaryolarını incelemeye başlayalım.
vSAN Arıza Senaryoları:
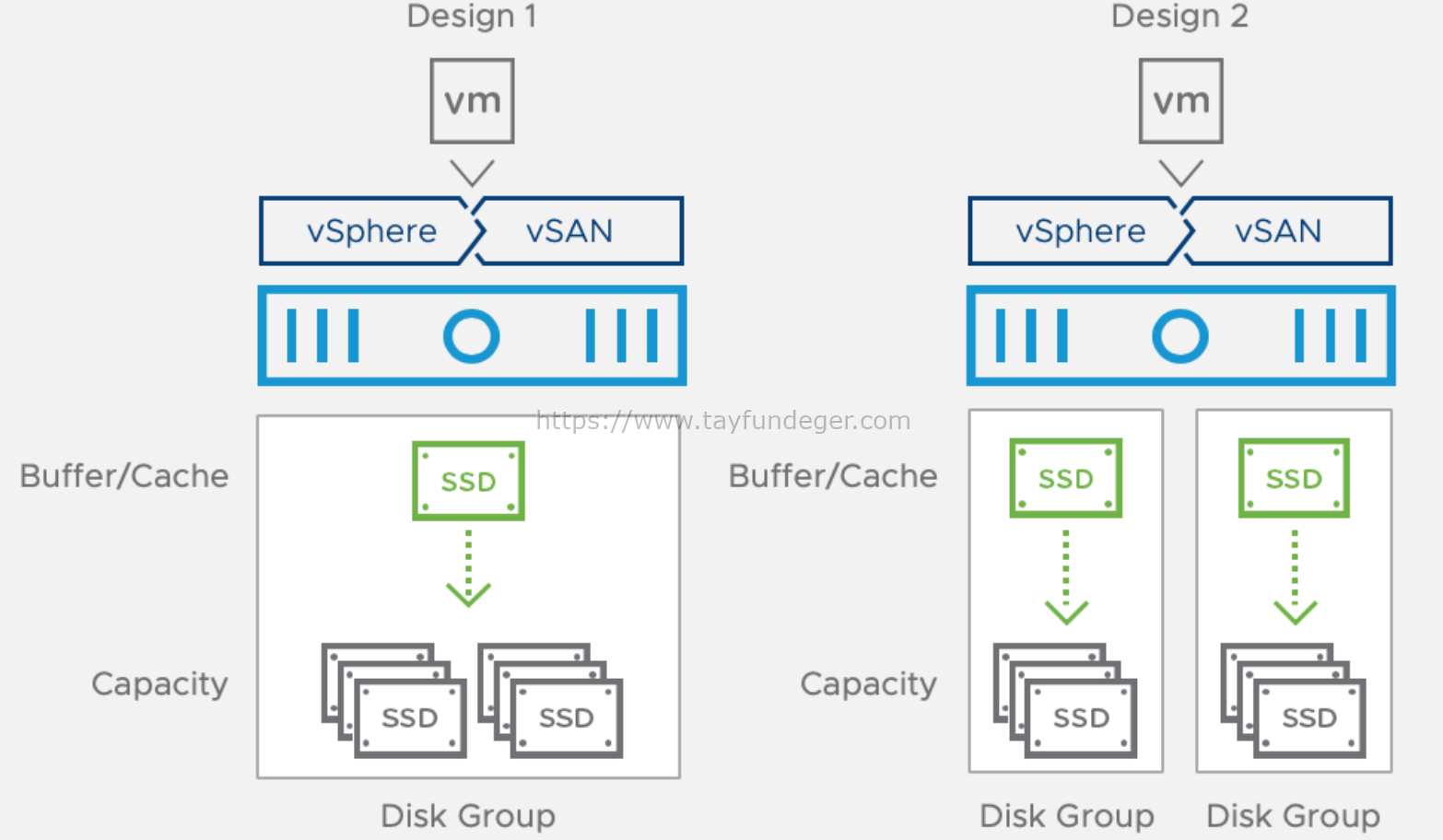
Şimdi, yukarıdaki 1 numaralı senaryoya baktığımızda 1 tane SSD cache bulunuyor ve 6 tane diskten oluşan bir disk grubuna bağlı durumda. Böyle bir durumda cache diskini kaynedersek veya arızalanırsa ne olur? Böyle bir durumda vSAN’da verileri kaybeder miyim? Önceki makalelerimi incelediyseniz orada da göreceksiniz. vSAN’da bir default policy vardır. Default storage policy RAID1 FTT = 1 ‘dir. Bu durum hatalı 1 cihazı tolere edeceğiniz anlamına gelir. Tabi siz burada storage policy’i RAID 0 olarak değiştirdiyseniz ozaman böyle hata tolere işlemi bulunmaz.
Disk grubu bir şekilde offline olduğunda cluster’da bulunan farklı vSAN node’larında bu verilerin ek bir kopyasının olduğunu unutmayın. Ek disk grubu oluşturmanız veya yapılandırmanız availability sağlamak için bir yol değildir. Availability sağlamak istiyorsanız SPBM yani Storage Policy Based Management kullanmanız gerekir. Storage Policy ile ilgili aşağıdaki yazmış olduğum makaleleri inceleyebilirsiniz.
VSAN – Storage Policy Data Locality
VSAN ve Storage Policies – Bölüm 1
VSAN ve Storage Policies – Bölüm 2
Arızalı olan disk değiştirilene kadar ve disk grubu rebuild edilene kadar 6 diskten oluşan disk grubundaki objeler (virtual machine ve dosyaları) offline’dir. Virtual machine’ler cluster’da bulunan ek kopyaları kullandığı için açık ve erişilebilir durumdadır.
Yukarıda bulunan 2 numaralı senaryoda ise, başarısızlık alanını azaltır çünkü artık arızalı bir cache diskiı 6 yerine yalnızca ilişkili 3 diske etki eder. Ayrıca bu etkilenen objelerin yeniden oluşturma süresini de azaltır. Yukarıda belirtmiş olduğum 1 numaralı senaryoda 1 disk grupta 1 cache disk 6 adet disk bulunuyordu. 2 numaralı senaryoda ise 2 farklı disk grup var 2 farklı cache disk bulunuyor.
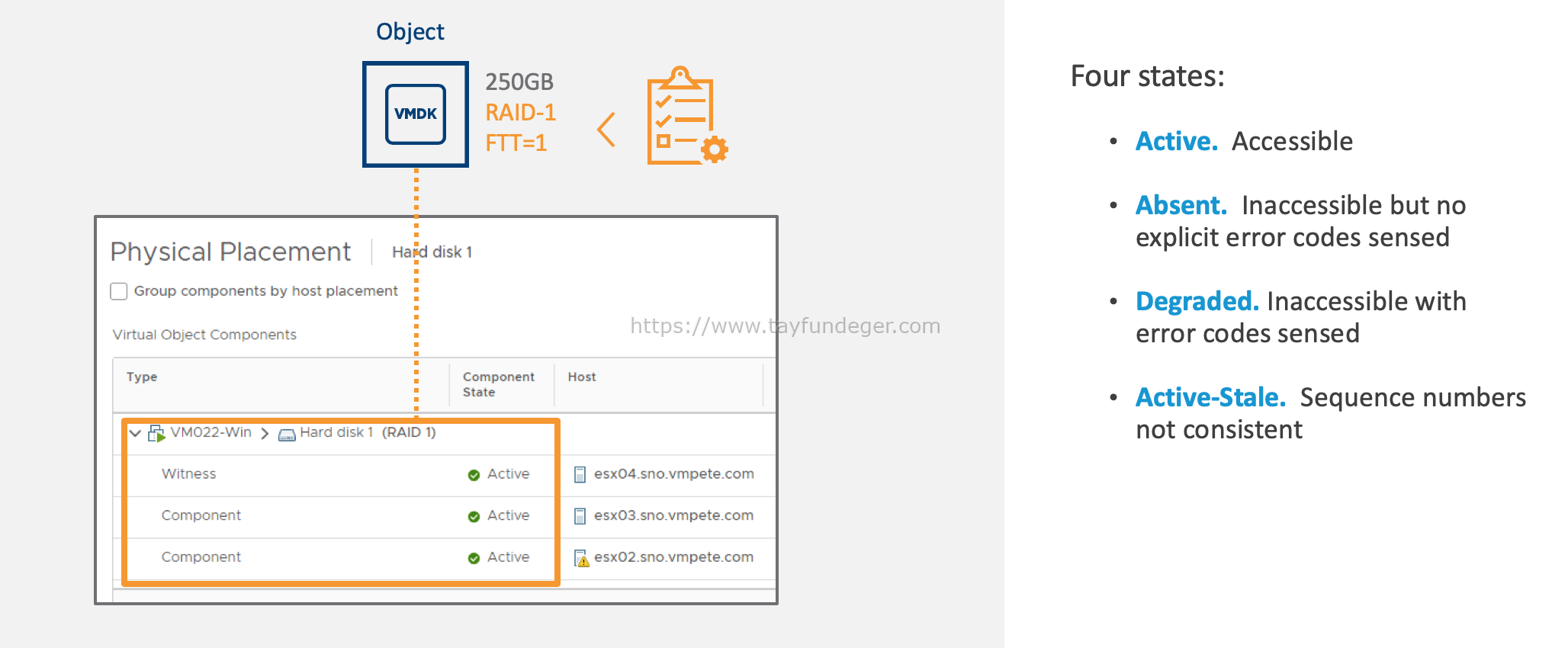
Eğer vSAN arızalı bir diski tanımlarsa, onu degraded yani bozulmuş olarak olarak etiketleyecek ve bozulan nesneleri tekrar onarmaya başlayacaktır. Daha önce bir çok makalemde bunu belirttim ancak tekrar belirtmek istiyorum. vSAN’da rebuild şlemi için 60 dakika bekleyeceği düşünülüyor ancak eğer cihazları absent yani yok olarak işaretlenir ise bu altyapıda bir network kesintisi olduğu veya ESXi host’un yeniden başlatıldığını düşünerek yani geçici bir kesinti olduğunu düşünerek 60 dakika bekler. Eğer bir disk arızalanır veya hata olduğu işaretlenir ise vSAN, Storage Policy’de belirtmiş olduğunuz ayarları sağlamak için hemen yenide yapılandırmaya başlar.
3 Node vSAN Arıza Senaryoları:
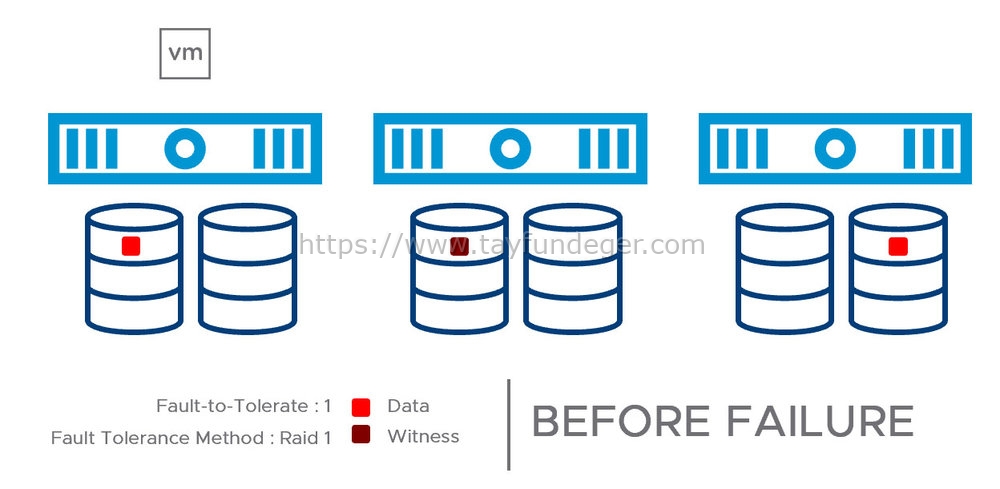
Her vSAN node’u üzerinde 2 kapasite diski olduğunu varsayalım. Bu şekilde 3 vSAN node’lu bir cluster’ımız var. FTT = 1 / FTM = RAID 1 etkileştirdiğimizi düşünelim. Yukarıdaki örneğe göre 2 node üzerine DATA ve yine tek node üzerinde witness bilgileri bulunmaktadır. FTT 1 olduğu için veriler ekstra farklı node üzerinde de tutulmaktadır. Böylece node’un biri down duruma geldiğinde cluster’da bulunan virtual machine’lerde bir kesinti olmayacaktır.
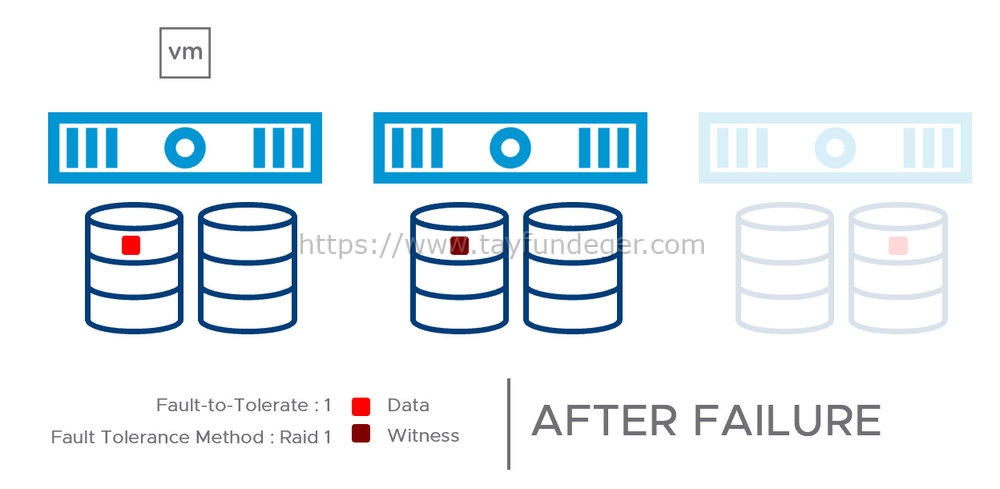
Bir node’da tamamen bir arıza meydana geldiğinde, yukarıdaki diyagramdaki gibi görünecektir. Elimizde verilerin hala iyi bir kopyasına sahip olduğumuzdan, virtual machine’lerin çalışmasına herhangi bir etkisi olmayacaktır. Bununla birlikte, vSAN’ın yedek kopyayı rebuild ve repair etmek için gerekli kaynaklara sahip olmayacağını belirtmek isterim. Çünkü 3 node’un bulunduğu bir ortamda 1 node down duruma geldiğinde verilerin bir kopyasını farklı node’lara dağıtılamaz. Bundan dolayı yedekliliğin tekrar sağlanması için down olan node’un tekrar kullanılabilir hale getirilmesi gerekir.
Peki arızalı diskler değiştirildiğinde veya tekrar sağlıklı duruma geldiğinde ne olur? Cluster’da yeterli alan oluşacağı için yedeklerin bir kopyası tekrar oluşacaktır.
4 Node vSAN Arıza Senaryoları:
Şimdi 4 düğümlü bir kuruluma bakalım. 4 node’lu bir cluster’da tek bir düğüm hatasını gösterir. 4 node’lu bir cluster ile verilerin geri kalan düğümde hemen yeniden oluşturulabilmesi dışında, 3 node’lu bir kuruluma oldukça benzer görünüyor. Ancak 4 vSAN konfigurasyonunda RAID-1 ve RAID-5 konfigürasyonlarında FTT = 1 destekleyebilir. Bu konfigürasyon, RAID-1 kullanıldığında bir arıza durumunda vSAN’ın kendi kendini repair/rebuild etmesinede izin verir. Bu son noktayı detaylandıralım. Kendi kendini rebuild/repair ne demek istiyoruz? Bununla kastettiğimiz, bir vSAN host’u başarısız olursa ve cluster’da kullanılabilir boş kaynaklar varsa, vSAN sorunu otomatik olarak çözebilir. RAID-1 ve FTT = 1 sayesinde 3 bileşen vardır. Bunlar; verilerin ilk kopyası, verilerin ikinci kopyası ve witness. Bunların tümü ayrı vSAN node’ları üzerinde bulunur. vSAN node’unun biri arızalanırsa, cluster’da kaynağın olması durumunda bileşen yeniden oluşturulabilir ve VM bir kez daha arızaya karşı tam olarak korunur.
Biraz değiştirelim. Şimdi 4 node’lu bir vSAN cluster‘ımız var ancak 2 tane vSAN node’u aynı anda arızalanır ise ne olur? Normal şartlarda FTT = 1 olduğu için virtual machine’lere erişim sağlanamazdı değil mi? 4 node’lu bir vSAN altyapısında verilerin iki kopyası olduğu için çalışmaya devam edebilir. Devam edebilir diyorum çünkü FTT = 1 olduğu durumlarda 4 node’lu bir vSAN altyapısında 2 adet node’un aynı anda arızalanması durumunda her virtual machine düzgün bir şekilde çalışmayabilir. Bu arızalanan vSAN node’u üzerinde bulunan datalara göre değişkenlik gösterir. Çünkü data’nın bir kopyasının tutulmadığı node’un ve witness node’unun kaybedildiğini düşünürsek hiç bir sorun olmaz. Ama data’nın ve kopyasıın bulunduğu 2 node aynı anda kaybedilirse çeşitli sorunlar çıkabilir.
2 node veya 3 node’lu cluster’da yukarıda bahsetmiş olduğum işlemler mümkün değildir. Bir vSAN node’unun arızalanması durumunda, eksik bileşeni yeniden oluşturmak için (rebuild/repair) yer yoktur. Verilerin hem kopyalarını hem de verileri ve bir witness ile aynı node üzerine yerleştirmiyor. Bu çok mantıklı çünkü node’u kaybetmeniz durumunda büyük bir data kaybı yaşanır ve bundan dolayı virtual machine’e erişim sağlanamaz. Bu, VMware’in FTT = 1, RAID-1 için minimumda 4 node’lu bir cluster önermesinin nedenlerinden biridir. Ancak RAID-5 yapılandırmaları seçilirse, bu rebuild/repair davranışına 4 node’da sahip olamayacağınızı unutmayın. Bir RAID-5 stripe 4 bileşenden oluştuğundan, her bileşen farklı bir vSAN node’una yerleştirilir. RAID-5 ile kendi kendini rebuild/repair yapabilmesi için, cluster’da en az 5 vSAN node’a ihtiyacınız olacaktır.
| Senaryo | vSAN Davranışı | Etki / Gözlemlenen VMware HA Davranışı |
|---|---|---|
| Cache diski hatası | Disk Grubu başarısız (failed) olarak işaretlenir ve üzerinde bulunan tüm bileşenler başka bir Disk Grubunda yeniden oluşturulur. | VM çalışmaya devam edecektir. |
| Kapasite disk hatası (Data Deduplication ve Compression AÇIK) | Disk Grubu başarısız (failed) olarak işaretlenir ve üzerinde bulunan tüm bileşenler başka bir Disk Grubunda yeniden oluşturulur. | VM çalışmaya devam edecek. |
| Kapasite disk hatası (Data Deduplication ve Compression KAPALI) | Başarısız olarak işaretlenen disk ve içindeki tüm bileşenler başka bir diskte yeniden oluşturulur. | VM çalışmaya devam edecek. |
| Disk Grubu hatası / offline | Disk Grubunda bulunan tüm bileşenler başka bir Disk Grubunda yeniden oluşturulacaktır. | VM çalışmaya devam edecek. |
| RAID / HBA kartı hatası | HBA / RAID kartı tarafından desteklenen tüm Disk Grupları yok olarak işaretlenecek ve mevcut tüm bileşenler diğer Disk Gruplarında yeniden oluşturulacaktır. | VM çalışmaya devam edecek. |
| ESXi host hatası | ESXi host üzerindeki bileşen, vSAN tarafından absent (yok) olarak işaretlenecektir – ESXi host geri gelmezse, bileşen yeniden oluşturma 60 dakika sonra başlatılacaktır. Rebuild/Repair işlemi. | VM, başka bir ESXi host üzerindeyse çalışmaya devam edecektir. Virtual machine arızalanan ESXi host’da çalışıyorsa, Virtual machine’in vSphere HA tarafından yeniden başlatması gerçekleşir. |
| ESXi host’un izolasyonu (network erişimini kaybetmesi vs.) | ESXi host’da bulunan bileşenler, vSAN tarafından absent (yok) olarak işaretlenecektir. ESXi host yeniden online olmaz ise, bileşen rebuild/repair işlemleri 60 dakika sonra başlatılır. | Virtual machine, başka bir ESXi host’da çalışmaya devam edecektir. Virtual machine, arıza ile aynı ana bilgisayarda çalışıyorsa, Virtual machine’in vSphere HA tarafından yeniden başlatması gerçekleşir. |
Son olarak, altyapınızda vSAN kullanıyorsanız gerçekten verileriniz emin ellerde diyebiliriz:) Elbette burada hata senaryolarını arttırabilirsiniz. Ancak karşılaştırmaları yaparken belirli mantık çerçevesinde yapmak lazım. Her türlü hata senaryosunu düşünecek olursanız fiziksel bir storage’ida down etmek mümkündür. Bundan dolayı en basit çözümler ile data güvenliğini nasıl sağlıyoruz bunu düşünmemiz gerekiyor. vSAN bize bu konuda oldukça fazla avantaj sağlıyor. Hata senaryoları ile ilgili buradaki makaleyide incelemenizi tavsiye ederim. Daha önce yazmış olduğum makaleleri okumanızı tavsiye ediyorum. Çünkü burada bahsetmiş olduğum bilgilerin bir kısmını aslında daha önce farklı makalelerde yazmıştım.
Umarım faydalı olmuştur.
İyi çalışmalar.